数据准备和特征工程(一)
不止是在学习机器学习和大数据的过程中,在各个学科的不同层面都会涉及到数据的获取和处理,从数据中发现规律从而利用规律已是主流趋势。这里将分享数据准备和特征分析中的常见概念和操作,对数据处理有一个基本的了解
- 使用Python语言(3.7)
- 使用jupyter编译器,你可以通过Anaconda安装管理
- You can get exercise files from:Link
数据来源
文件中的数据
- CSV文件
- Excel文件
- 图像文件
数据库中的数据
网页上的数据
- 爬虫
来自API的数据
感知数据
我们侧重于文件中的数据
- 文本文件
1
2
3
4
5# 使用文件方式打开
f = open(csv_file)
data = csv.reader(f)
for line in data:
print(line)1
2
3
4
5
6# 数据科学中常使用的是pandas
import pandas as pd
csv_file = "/home/data/file/cities.csv"
df = pd,read_csv(csv_file) # 得到一个dataFrame对象
# pd.read_csv(csv_file, index_col=0) # 指定某一列为索引,而不是默认数字索引
df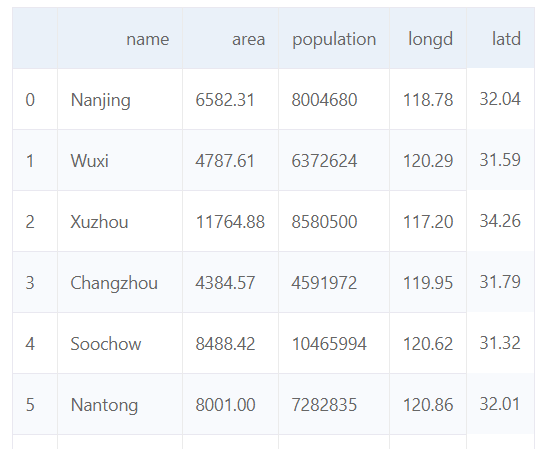
1
2
3df.head() # 显示数据前几行
df.shape # 查看数据形状(行列值)
df.info() # 查看数据信息1
2
3
4
5
6
7
8
9
10
11# df.info()输出:
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 13 entries, 0 to 12
Data columns (total 5 columns):
name 13 non-null object
area 13 non-null float64
population 13 non-null int64
longd 13 non-null float64
latd 13 non-null float64
dtypes: float64(3), int64(1), object(1)
memory usage: 600.0+ bytes- 使用Excel处理数据
1
2
3
4# Excel对处理一些较小型的数据有很强大的功能
# 在Python中操作excel需要安装第三方模块
!pip install xlrd -t /home/external/external-libraries
!pip install openpyxl -t /home/external/external-libraries1
2
3
4
5import sys
sys.path.append('/home/external/external-libraries')# 加入环境变量(导包)
jiangsu = pd.read_excel("/home/data/file/jiangsu.xls")
jiangsu # dataFrame对象
jiangsu.to_excel('work/files/jiangsu.xlsx') # 转化为电子excel形式- 数据清洗
1
2cpi = pd.read_excel("/home/data/file/cpi.xls")
cpi.head(4) # 我们发现有索引和缺失值的问题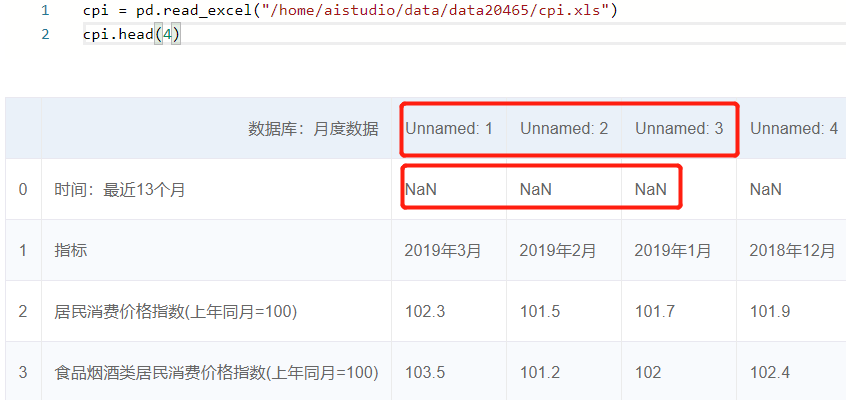
1
2
3
4
5
6
7
8
9cpi.columns = cpi.iloc[1]
cpi = cpi[2:]
cpi.drop([11, 12], axis=0, inplace=True)
cpi['cpi_index'] = ['总体消费', '食品烟酒', '衣着', '居住', '生活服务', '交通通信', '教育娱乐', '医保', '其他']
cpi.drop(['指标'], axis=1, inplace=True)
cpi.reset_index(drop=True, inplace=True)
cpi.columns.rename('', inplace=True)
cpi
cpi.info()1
2
3for column in cpi.columns[:-1]:
cpi[column] = pd.to_numeric(cpi[column]) # 转为float类型
cpi.dtypes- 绘制图表
1
2
3
4%matplotlib inline
import matplotlib.pyplot as plt # ⑬
plt.bar(cpi.iloc[5, :-1].index, cpi.iloc[5, :-1].values)# x,y坐标
plt.grid()- 图像文件
- PIL:python图像处理库
1
2
3
4from PIL import Image
color_image = Image.open("home/data/images/baobao.jpg")
color_image
color_image.shape # 查看维度信息1
2gray_image = Image.open("work/images/laoqi.png").convert("L")
gray_image # 转换为灰度图- 图像数据即是多维的像素值
1
2
3
4
5
6import numpy as np
color_array = np.array(color_image)
color_array.shape
# 可以使用PIL提供的方法
img = np.asarray(color_image) # image转换为array
Image.fromarray(img) # array转换为image- 也可以使用matplotlib库操作
1
2
3
4import cv2 # opencv是专业的图像处理库
img = cv2.imread('work/images/laoqi.png', 0) # 数组形式
plt.imshow(img, cmap = 'gray', interpolation = 'bicubic')
plt.xticks([]), plt.yticks([])结语
以上介绍了常见的数据形式和最基本的处理方法,使用Python做数据处理分析有很大的优势,
pandasmatplotlibnumpycv2等库提供了很多好的操作数据的方法,后面会逐步积累!