Python基础
- 这里将Python常用的基础知识整理回顾,实践出真知
- IDE使用PyCharm
Python基操
字符串
1 | mystr = 'RoyKun' |
常见数据类型及操作
- IDE中会有操作提示
1 | # 列表:以中括号表现形式的数据集合,可以放任意类型的数据 |
1 | # 元祖:以小括号形式表现的数据集合,可以存任意类型的数据 |
1 | # 字典:以大括号形式表现的数据集合,元素使用键值对表示 |
1 | # 集合set:以大括号表示的数据集合,无序,且不能重复 |
- 列表、元素、集合都叫做数据容器,可以相互转换
1 | my_list = [1,2,2] |
enumerate()函数用于将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列
也是后面拆包的常用操作
1 | for index, value in enumerate(['apple', 'banana']): |
1 | # 针对字典 |
函数相关操作
1 | # 不定长参数函数 |
1 | # 递归函数:传递回归,即在函数内部再次调用函数 |
1 | # 匿名函数:没有名称的函数 |
1 | # 高阶函数 |
装饰器
1 | # 闭包 |
1 | # 装饰器本质上是一个函数,可以对原函数的功能进行扩展,不影响原函数的定义和调用 |
- 切片
1 | str = 'RoyKun' |
文件操作
- 主要用到
open函数和os包
1 | # 读取键盘输入 |
1 | # 打开文件使用open函数 |
1 | # 其他方法 |
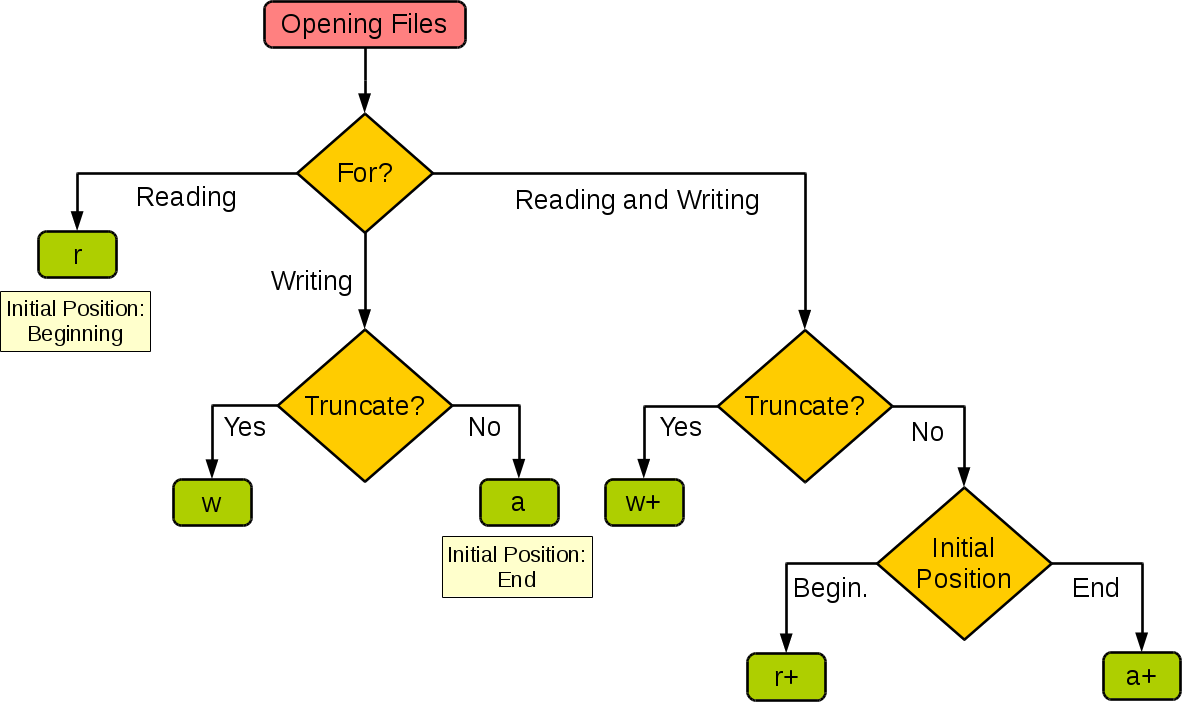
对于打开文件的模式总结如下图:
文件对象还包含以下属性:
| 属性 | 描述 |
|---|---|
| file.closed | 返回true如果文件已被关闭,否则返回false。 |
| file.mode | 返回被打开文件的访问模式。 |
| file.name | 返回文件的名称。 |
| file.softspace | 如果用print输出后,必须跟一个空格符,则返回false。否则返回true。 |
- os模块提供了帮你执行文件处理操作的方法,比如重命名和删除文件
1 | import os |
json序列化
JSON (JavaScript Object Notation) 是一种轻量级的数据交换格式,它基于ECMAScript的一个子集
使用
json模块来对 JSON 数据进行编解码,主要包括json.dumps()对数据进行编码json.loads()对数据进行解码
Python 编码为 JSON 类型转换对应表:
Python JSON dict object list, tuple array str string int, float, int- & float-derived Enums number True true False false None null
高级操作
面向对象
- 类、继承、部分特殊方法等需要了解掌握
- 可参看菜鸟教程,过一遍就OK:
https://www.runoob.com/python3/python3-class.html
异常处理
常见的异常处理方法:
- 使用
try/except:检测try语句块中的错误,从而让except语句捕获异常信息并处理 - 可以使用
raise语句自己触发异常 - 异常可以是python标准异常,也可以继承并自定义
- 使用
参看教程,过一遍即可
自定义包/模块
大型的程序需要自定义很多的包,既增强代码的可读性,也便于维护
需要注意:
__name__属性
1
2
3
4
5
6
7# 如果我们想在模块被引入时,模块中的某一程序块不执行,我们可以用__name__属性,使该程序块仅在该模块自身运行时执行
# Filename: using_name.py
if __name__ == '__main__':
print('程序自身在运行')
else:
print('我来自另一模块')1
2
3
4
5
6$ python using_name.py
程序自身在运行
$python
>>> import using_name
我来自另一模块
迭代器
迭代器是访问集合元素的一种方式,对于可以使用for循环遍历的类型(字典、列表、字符串等)都可以迭代
有两个基本的方法:
iter()和next()1
2
3
4
5
6
7# 如果可以查看到 __iter__ 方法,即是可迭代对象
result = dir([1,2])
print(result)
# isinstance() 函数来判断一个对象是否是一个已知的类型,类似 type()
a = 2
isinstance (a,int) # True把一个类作为一个迭代器使用需要在类中实现两个方法
__iter__与__next__1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39class MyIterator:
def __iter__(self): # 返回一个特殊的迭代器对象
self.a = 1
return self
def __next__(self): # 返回下一个迭代器对象
x = self.a
self.a += 1
return x
myclass = MyIterator()
myiter = iter(myclass) # 迭代变量在___iter__中,必须使用iter()方法
print(next(myiter)) # 1
print(next(myiter)) # 2
print(next(myiter)) # 3
print(next(myiter)) # 4
print(next(myiter)) # 5
##################################################################
class MyIterator:
def __init__(self):
self.list1 = [1,3,5,6]
self.current_index = 0
def __iter__(self):
# 返回一个特殊的迭代器对象
return self
def __next__(self):
if self.current_index < len(self.list1):
# 返回下一个迭代器对象
x = self.list1[self.current_index]
self.current_index += 1
return x
else:
raise StopIteration()
myiter = MyIterator() # 实例化迭代器
for value in myiter: # for循环就是这么强大:不用next也不用raise异常啊啊啊
print(value)- 迭代器和生成器的好处是:根据需要每次生成一个值,相当于保存了之前的状态下次继续而不是从头开始,节省内存
生成器
生成器是特殊的迭代器
生成器的创建有两种方式
- 使用类似列表生成器
1
2result = (x for x in range(5)) # 换成小括号
value = next(result) # 0- 使用
yield创建生成器
1
2
3
4
5
6
7
8def func():
for i in range(5):
print('before') # 例如:在深度学习项目中将数据加载部分放在这,每次只会将一部分数据拉进内存,节省消耗
yield i # 每次迭代在这里暂停,下次迭代继续执行
print('after')
gene = func()
print(next(gene)) # 或者使用for循环输出注:迭代器和生成器的迭代只能往后不能往前
线程和进程
- 使用
threading创建子线程
1 | import threading |
- 主线程一般会等待子线程结束再退出
- 可以通过设置守护线程,主线程结束即全部退出
1 | if __name__ == '__main__': |
- 互斥锁——线程同步
1 | # 多个线程之间同时操作全局变量就会出问题,需要上锁 |
- 每创建一个进程操作系统都会分配运行资源,真正干活的是线程,每个进程会默认创建一个线程
- 多进程需要多个CPU核,而多线程是在一个核里进行资源调度,可以结合并行并发的概念理解
1 | import multiprocessing |
类似的可以使用守护进程退出子进程
也可以使用
Precess.terminate()终止进程之间是独立的,不共享全局变量
那么进程之间如何通信呢?消息队列
1 | queue = multiprocessing.Queue(3) # 默认可以存任意多数据 |
- Queue模块中常用到的方法
- Queue.qsize() 返回队列的大小
- Queue.empty() 如果队列为空,返回True,反之False
- Queue.full() 如果队列满了,返回True,反之False
- Queue.full 与 maxsize 大小对应
- Queue.get([block[, timeout]])获取队列,timeout等待时间
- Queue.get_nowait() 相当Queue.get(False)
- Queue.put(item) 写入队列,timeout等待时间
- Queue.put_nowait(item) 相当Queue.put(item, False)
- Queue.task_done() 在完成一项工作之后,Queue.task_done()函数向任务已经完成的队列发送一个信号
- Queue.join() 实际上意味着等到队列为空,再执行别的操作
小结
还有一些常见的操作比如Python连接数据库、解析XML数据等,可以结合项目学习加深理解。每一门语言都是一个完备的体系,很多内容可能现在用不到,提前了解为好。

注:要注意身体,切勿慢性zs!晚安