Python爬虫系列——数据请求
爬虫是一种按照一定的规则,自动的抓取网页信息的程序或者脚本,这样的程序可以用很多语言实现,但是人生苦短大家都用python,所以你要有python基础知识(跟着我的博文走一遍就好啦)。
Python爬虫的方式有多种,从使用爬虫框架获取数据到解析提取,再到数据存储,各阶段都有不同的手段和类库支持。虽然不能一概而论哪种方式一定更好,毕竟不同案例需求和不同应用场景会综合决定采取哪种方式,但对比之下还是会有很大差距。
Selenium
Selenium是一个用于Web应用程序测试的工具,但是处理一些小爬虫很方便
关键命令
find_element(s)_by_tag_name
find_element(s)_by_css_selector
案例说明——爬取商城商品信息
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26from selenium import webdriver
import time
browser = webdriver.Chrome()
browser.set_page_load_timeout(30)
browser.get('http://www.17huo.com/search.html?sq=2&keyword=%E7%BE%8A%E6%AF%9B')
page_info = browser.find_element_by_css_selector('body > div.wrap > div.pagem.product_list_pager > div')
# print(page_info.text)
pages = int((page_info.text.split(',')[0]).split(' ')[1])
for page in range(pages):
if page > 2:
break
url = 'http://www.17huo.com/?mod=search&sq=2&keyword=%E7%BE%8A%E6%AF%9B&page=' + str(page + 1)
browser.get(url)
browser.execute_script("window.scrollTo(0, document.body.scrollHeight);")# 屏幕滚动,不然会load不完整
time.sleep(3)
# body > div.wrap > div:nth-child(2) > div.p_main > ul
goods = browser.find_element_by_css_selector('body > div.wrap > div:nth-child(2) > div.p_main > ul').find_elements_by_tag_name('li')
print('%d页有%d件商品' % ((page + 1), len(goods)))
for good in goods:
try:
title = good.find_element_by_css_selector('a:nth-child(1) > p:nth-child(2)').text
price = good.find_element_by_css_selector('div > a > span').text
print(title, price)
except:
print(good.text)如图,获取商品页面信息

使用谷歌浏览器,在页面元素处右键检查可以查看页面代码,使用
Copy selector得到定位信息传入方法,如图所示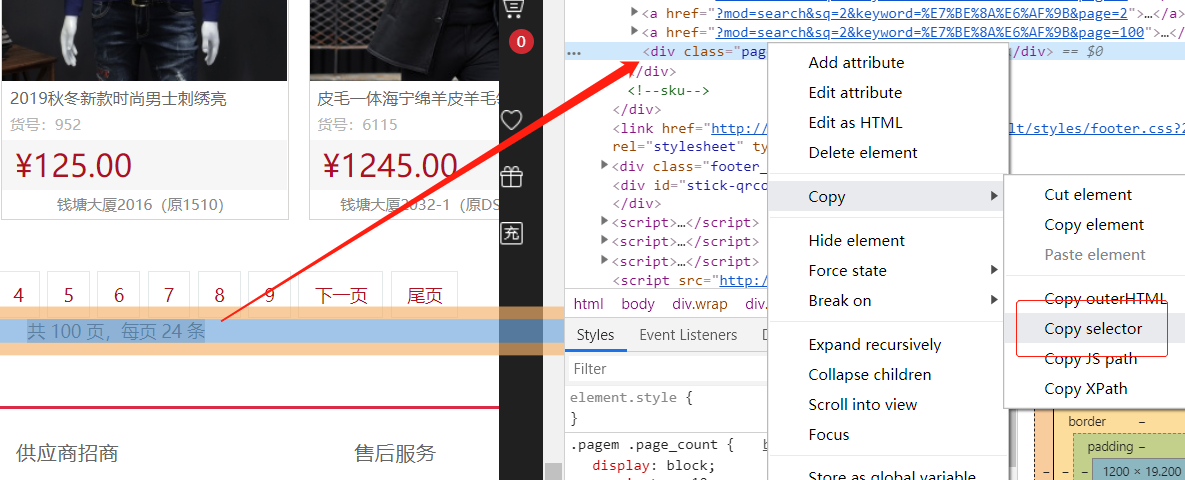
注:定位信息的获取只需观察HTML标签的所属关系即可发现规律
使用webdriver接口需要安装驱动
注:一般情况下需要将下载的驱动放在自定义目录下并加入系统环境变量,但我试了不行,于是放在谷歌浏览器启动目录下,也不行!最后放在python.exe目录下,成了!
requests
毫无疑问这是最常用的爬虫库了,极大简化了操作,一切动力都来自于根植在 requests 内部的 urllib3,来个小demo:
1
2
3
4
5
6
7
8
9import requests
print(dir(requests)) # 查看包含的方法
url = 'http://www.baidu.com'
r = requests.get(url)
print(r.text)
print(r.status_code)
print(r.encoding)传递参数
1
2
3params = {'k1':'v1', 'k2':'v2'}
r = requests.get('http://httpbin.org/get', params)
print(r.url) # http://httpbin.org/get?k1=v1&k2=v2二进制数
1
2
3
4
5
6# 下载图片并保存
from PIL import Image
from io import BytesIO
r = requests.get('http://i-2.shouji56.com/2015/2/11/23dab5c5-336d-4686-9713-ec44d21958e3.jpg')
image = Image.open(BytesIO(r.content))
image.save('download/meinv.jpg')json处理
1
2
3r = requests.get('https://github.com/timeline.json')
print(type(r.json))
print(r.text) # 返回字符串原始数据
1
2
3
4r = requests.get('http://i-2.shouji56.com/2015/2/11/23dab5c5-336d-4686-9713-ec44d21958e3.jpg', stream = True)
with open('download/meinv2.jpg', 'wb+') as f:
for chunk in r.iter_content(1024): # 将二进制数据分批写入
f.write(chunk)处理表单
1
2
3
4
5
6import json
form = {'username':'user', 'password':'pass'}
r = requests.post('http://httpbin.org/post', data = form) # 信息保存在form
print(r.text)
r = requests.post('http://httpbin.org/post', data = json.dumps(form)) # 信息保存在json
print(r.text)cookie
1
2
3
4
5
6
7
8
9
10
11
12# HTTP协议本身是无状态的。什么是无状态呢,即服务器无法判断用户身份。Cookie实际上是一小段的文本信息(key-value格式)。客户端向服务器发起请求,如果服务器需要记录该用户状态,就使用response向客户端浏览器颁发一个Cookie。客户端浏览器会把Cookie保存起来。当浏览器再请求该网站时,浏览器把请求的网址连同该Cookie一同提交给服务器。服务器检查该Cookie,以此来辨认用户状态
url = 'http://www.baidu.com'
r = requests.get(url)
cookies = r.cookies
for k, v in cookies.get_dict().items():
print(k, v) # BDORZ 27315
# 访问网站可以带上我们的cookie,可以不再重新登录
cookies = {'c1':'v1', 'c2': 'v2'}
r = requests.get('http://httpbin.org/cookies', cookies = cookies)
print(r.text) # 这是一个测试http请求的网站重定向
1
2
3
4
5# 有些网站会跳转,可以查看记录
r = requests.head('http://github.com', allow_redirects = True)
print(r.url) # https://github.com/
print(r.status_code)
print(r.history) # 查看重定向历史
实例——爬取豆瓣信息
1 | import requests |
- 上面是使用登录后的cookie爬取页面信息,cookie可以在浏览器的开发者工具Network中找到
- 也可以使用用户名密码登录,但是可能需要输入验证码,比较繁琐
1 | import requests |
Scrapy
对于简易的项目可以使用上面的方式结合数据解析爬取,但是从数据的请求到存储是一个比较复杂的过程,如果项目需求较大,一步步操作效率很低,所以推荐使用scrapy爬虫框架
框架的整个流程如图所示:官网链接
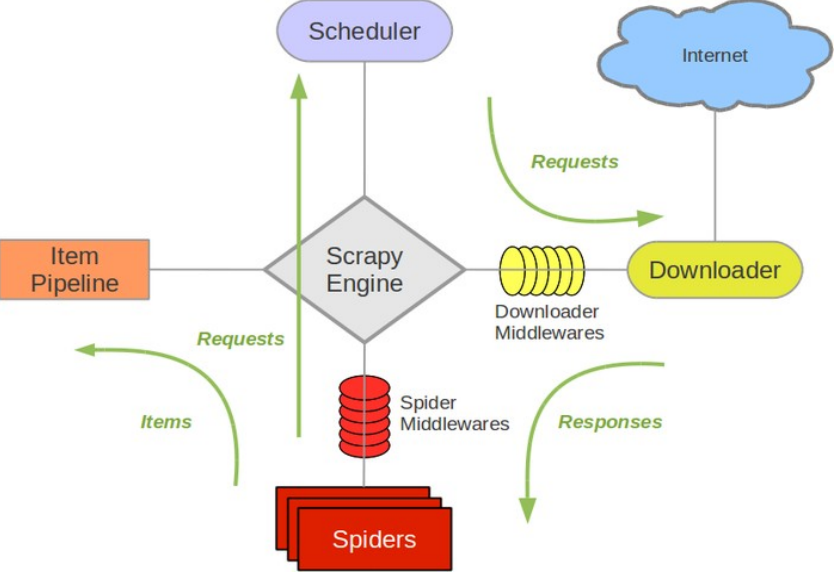
主要结构包括
- 引擎(Scrapy Engine) 【心脏】
负责Spider、ItemPipeline、Downloader、Scheduler中间的通讯,信号、数据传递等
- 调度器(Scheduler) 【脑袋】
负责接受引擎发送过来的Request请求,并按照一定的方式进行整理排列,入队,当引擎需要时,交还给引擎。
- 下载器(Downloader)
负责下载Scrapy Engine(引擎)发送的所有Requests请求,并将其获取到的Responses交还给Scrapy Engine(引擎),由引擎交给Spider来处理
- 蜘蛛(Spiders) 【胃…】
负责处理所有Responses,使用xpath解析页面内容,并将需要跟进的URL提交给引擎,再次进入Scheduler(调度器),并生成解析后的结果Item。
最后返回的这些Item通常会被持久化到数据库中(使用Item Pipeline)或者使用Feed exports将其保存到文件中。
- 项目管道(Item Pipeline)
负责处理Spider中获取到的Item,并进行进行后期处理(详细分析、过滤、存储等)的地方
- 下载器中间件(Downloader Middlewares
可以自定义扩展下载功能的组件
- 蜘蛛中间件(Spider Middlewares)
可以自定义扩展的功能组件比如进入Spider的Responses;和从Spider出去的Requests
- 调度中间件(Scheduler Middlewares)
使用scrapy爬取单个页面:
1 | import scrapy |
- 在pycharm的terminal中使用命令:
scrapy runspider scrapyDemo.py -o houseInfo.csv - 爬取上面的页面你会发现怎么都得不到数据,原因是:

感受到了对小白满满的恶意!没事,先投降,以后再搞他 ……
注:在获取xpath表达式的时候一定要用分块分割的思想,获取内容时要展开到最底层使用对应的方法,熟悉常见的xpath表达式符号的意义:
///@[表达式]text()position()last()
- 使用scrapy爬取多张页面:
1 | class tagSpider(scrapy.Spider): |
scrapy创建项目
推荐使用scrapy创建项目再爬取数据
在合适的目录下,命令行:
scrapy startproject ProjectName创建,目录结构: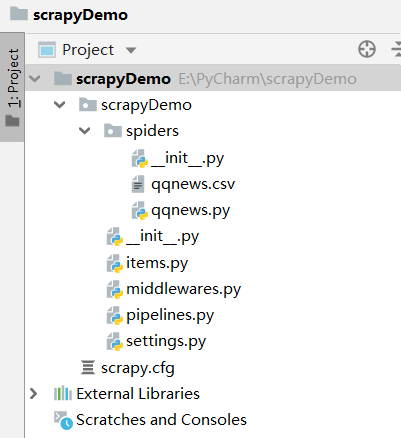
以下框架介绍可以先整体阅读一遍再实操,是一个整体
在spiders下面创建代码:
1 | import scrapy |
从主页面获取多个新闻页面链接,回调给具体的新闻解析方法parseNews()
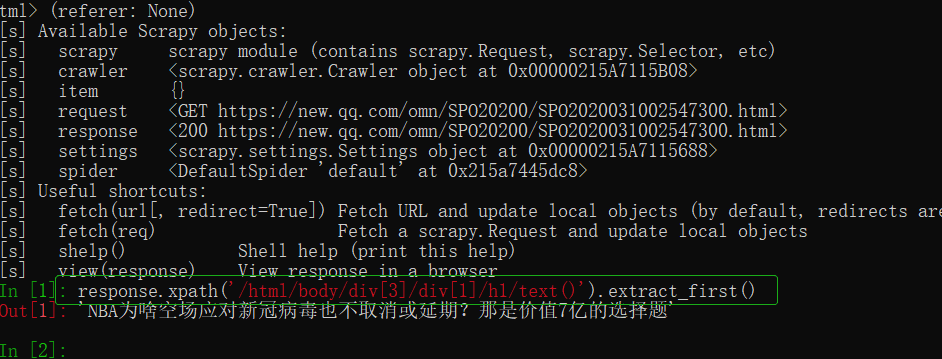
我们可以使用scrapy自带的调试工具,查看页面是否能爬取成功:
- 在终端使用命令:
scrapy shell http://爬取的网址,可以执行xpath方法
- 除了spider之外,框架还提供了其他类型的爬虫
- CSVFeedSpider
- CrawlSpider
- XMLFeedSpider
- 在
ProjectName/items.py下定义数据字段:
1 | import scrapy |
可以使用ItemLoader填充:
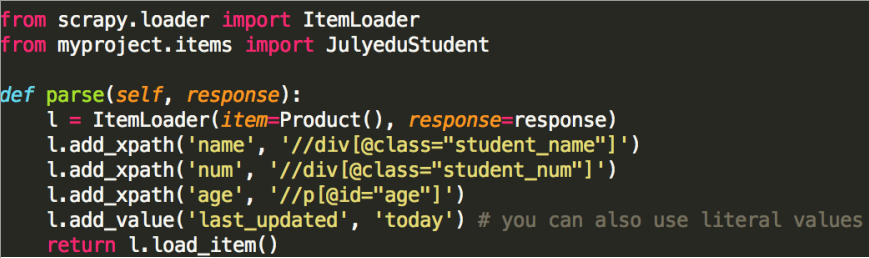
- 获取数据字段Item之后,被发送给Item Pipeline,然后多个组件按照其中定义的方法顺序处理这个item
- 经常会实现以下的方法:
1 | import json |
Item Pipeline还提供了一些可以重用的Pipeline,其中有
filesPipeline和imagesPipeline,用于图片和文件下载
以上即是scrapy项目使用的大致流程,如果想详细了解提到的组件,可以参考链接,并结合官网内容,因为有些东西更新了,比如extract()方法变为
getall(),extract_first()方法变为get()
接下来以项目为主介绍详细的使用方法!
实例——爬取豆瓣图书信息
晚安!
